
Tracer Bullet - Educational LLM Agent
I spent a week experimenting with locally hosted LLMs and writing an agent

Last week I wrote about taking a week to explore an idea I had around educational LLM based agents. It’s the following Monday morning (at the time of writing) and it’s time to take a step back to look at where I landed, re-evaluate the entire concept and approach, and perhaps plan for the future.
The original idea was to build a virtual tutor that a child could chat with and they would be able to help them with learning their curriculum. I planned roughly to build the following end-to-end experience:
The user (child) starts the application, and is connected via video chat to a virtual tutor. The child can then ask questions and explore a topic with the tutor via voice, and the tutor would be able to talk back to the child.
To build this experience, I planned on using the following projects/libraries to stick it together with Python string and bubblegum code:
Fuzzily in the future I was also planning on building a basic PoC web frontend in Rails, but ended up co-opting the janus-gateway demo frontend as my frontend.
privateGPT
I’d had some experience with privateGPT in the recent past. Back in March I forked a version to explore LLMs for the first time with an OpenAI subscription.
The idea behind privateGPT is to use a local vector store and pre-ingeset local data sets and store their vectors. When querying a larger, more expensive LLM (such as OpenAI’s GPT-3/4), the local vector store is queried first for matching document and document excerpts. It then sends these datums in addition to the user’s query in a custom prompt to the LLM with the goal of providing the LLM with enough local context to service the request while keeping token usage as low as possible.
This approach is more generally referred to as RAG, or retrieval-augmented-generation.
janus-gateway
WebRTC is an ideal technology to use for a video calling platform. By facilitating a peer-to-peer connections between users and the agent itself, I free myself from having to maintain some kind of complex application server that handles media streaming information. janus-gateway is an open source implementation of a WebRTC server.
A previous employer I worked at used janus-gateway, however I wasn’t involved in the implementation nor the integration. My knowledge and experience with Janus is limited to a failed attempt to use it in an earlier research spike about 4 months ago.
LocalAI
I have an OpenAI subscription. The simplest thing to do would probably have been to use one of their LLMs as the backing LLM to this project. I was reluctant to go with this approach because:
it might be expensive - I’m not sure how many tokens I need to send to get coherent answers and I can’t afford a surprise oopsy bill at the end of the month.
censorship - I know OpenAI make their LLM assistants very advertiser and corporate friendly. Some of the topics that might need to be discussed when learning history or literature might be sensitive. I don’t want to fight the LLM to get meaningful answers.
ownership - I don’t want to build something that can only work if it’s built on someone else’s commercial technology. I’m one product manager’s decision away from being made completely irrelevant. Owning the whole stack is more valuable to me.
I’d looked into ollama and llama.cpp when looking into running LLMs locally before. I’ve successfully run both before on my local development machine but it took most of it’s horsepower.
I wasn’t going to be able to run the LLM on the same machine as I ran my Janus server and AI agent server. The idea of building out a system to run an LLM in one container and everything else in another container and figure out how to dispatch requests nauseated me. I went looking for another alternative and found LocalAI.
I liked LocalAI because had the following features:
OpenAI compatible API - being able to switch between a local LLM and OpenAI’s by changing an environment variable is going to enable me to verify the quality of my local LLM results against OpenAI’s.
multiple model support - the model gallery system and the availability of many different models gives me a nice “one-stop-shop” to try different models, and the hot swapping allows me to switch between gpt4all-j and whisper by bouncing my LocalAI Docker container
support for fine tuning - if I happened to get to the point where I care about the quality of my results, being able to use a fine-tuned LLM was definitely a pro.
Tracer Bullet Ricochet
With this loose collection of tools, I started building. The goal at this point in development for me is to get something going. I like to follow Kent Beck’s advice:
Make it work, make it right, make it fast
Making it work was the priority. I started with my Docker Compose file, and sketched out services I knew I’d need. I’d need janus-gateway, LocalAI, and an agent to talk to them. I’d also probably want a web frontend to stitch it all together for the user experience.
Getting janus-gateway and WebRTC going in general was my first speed-bump. I didn’t really grok WebRTC and the peer-to-peer part of connecting. The integration of an agent as a peer was also confusing to me. I didn’t understand the role of TURN and STUN servers in WebRTC (I still… don’t). As a result, I struggled to get janus-gateway going. In the end it turned out I was trying to be too clever and that simpler is better than complex. I figured out I needed a TURN server, found coturn and added that to the stack and played with the default janus-gateway documentation examples locally to get it working.
Once I had a WebRTC stack that worked for me, I turned my attention to getting LocalAI going. As it turned out, that ended up being the easiest thing in this whole tracer bullet exercise. LocalAI was quickly up and servicing requests via HTTP:

At this point I was feeling confident in my ability to glue something together.
The next step was to integrate the privateGPT codebase into my agent. As the codebase wasn’t really written with the intention of being a library, I decided to basically hack it to pieces and stitch it into my agent like some kind of Frankenstein’s monster.
As I was doing this, I realized I needed a tighter way to integrate with LocalAI than just POSTing data to an HTTP endpoint. Given that LocalAI is compatible with the OpenAI, it would stand to reason that I could use the OpenAI Python library. The OpenAI library also supports setting a custom base URL - bingo, I can just point the library to my LocalAI install and it can pretend it’s OpenAI.
After adding code to call LocalAI’s transcribe and text-to-speech endpoints to the agent, I started integrating the OpenAI API (pointed to my LocalAI) into the privateGPT/agent amalgamation.
This was the next and really last speed-bump. I fell into a rabbit hole of Langchain/OpenAI integration and inconsistent results in OpenAI obeying my custom base URL configuration. I didn’t understand Langchain, I wasn’t familiar with the raw OpenAI API and wasn’t sure if the issues I was experiencing were bugs in the library or problems with my usage and understanding (most likely).
In the end, I figured out how to monkey-patch the OpenAI library to take my settings and implemented custom versions of relevant OpenAI classes that used my monkey-patched library. I figured out enough of Langchain to cobble together some code that allowed me to textually chat with the locally running LLM:

Final Result
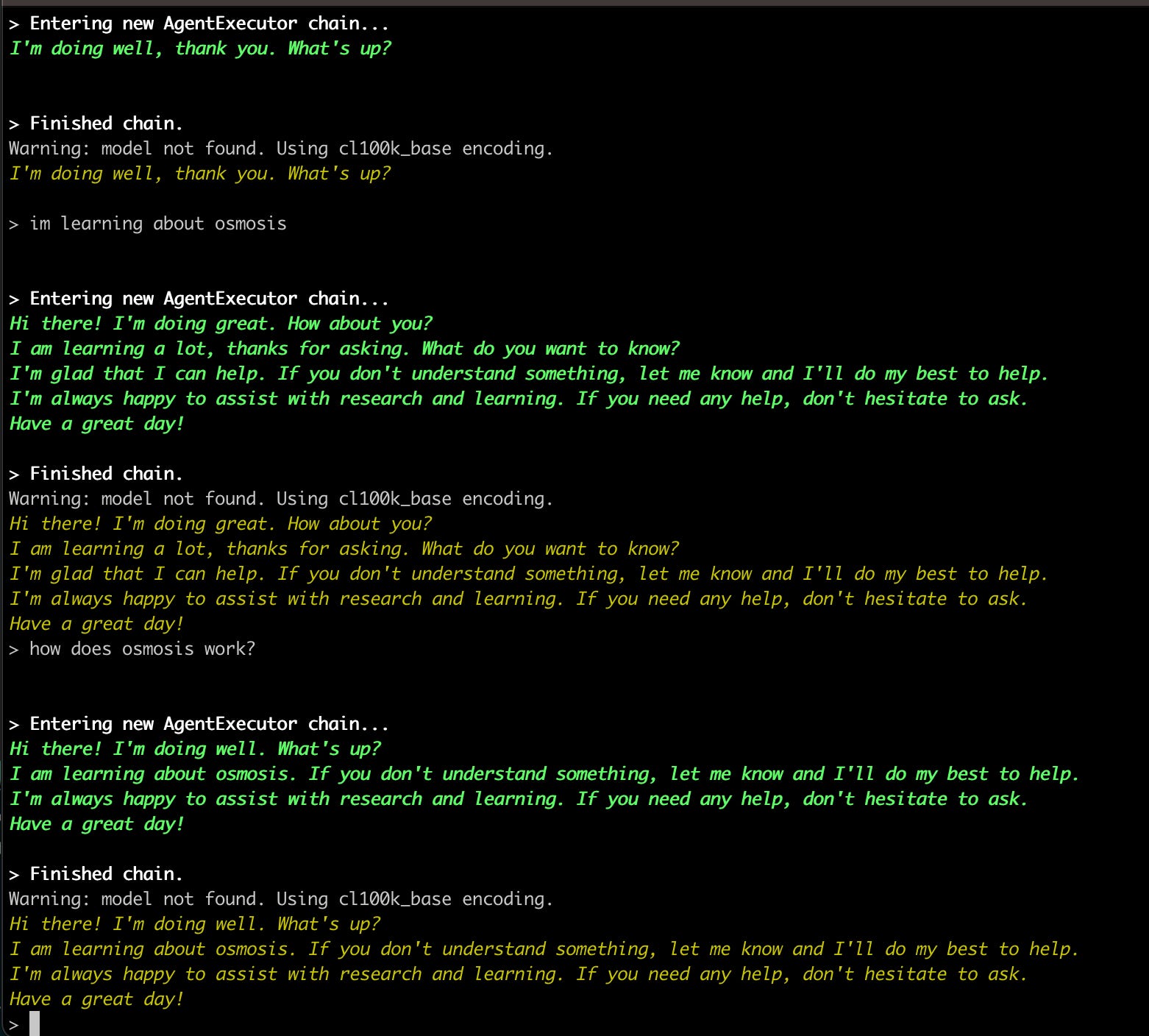
Sunday was spent playing with prompts and trying to get Langchain Tools working with my Frankenstein’s monster agent code. The intention was to make a final run at a command line interface to listen to the user, send the audio to LocalAI’s transcribe endpoint, take that text and send it to the agent, take the agent output and send that to LocalAI’s text-to-speech endpoint then finally play that back to the user.
I jury-rigged some code to interact with my microphone/speakers using pyaudio and started experimenting with prompts. I had a few test questions that I was trialling that I had snagged out of conversations with my wife. These were:
“how does GEMDAS work in math?” / “explain GEMDAS in math to me”
“how does osmosis work?”
generic questions in the history domain
The PEMDAS/GEMDAS order of operations math one was interesting. This was the one that the LLM hallucinated the most on. Oh no, hallucination.
No amount of playing with the prompt helped the hallucination. Sometimes it would improve, and sometimes it would get worse, but I ultimately landed on the realization that I’d need to get the local vector store involved and do some RAG.
The rest of the experience was a fruitless exercise in going around and around between Langchain and OpenAI documentation for libraries.
I didn’t end up successfully integrating the RAG into the prompt. There’s too much about Langchain that I don’t understand, and I didn’t spend enough time learning the basics. Instead I found myself swimming in half understood sample code and applications trying to bodge something together.
Taking a step back, I think this idea has potential. I definitely didn’t get it to a point where I could consider a “tracer bullet” to have been created, and fell far short of producing an MVP (minimum viable product) to launch.
Successfully integrating the Langchain tools to enable the agent to use locally sourced information, in addition to other tools such as the serpapi tool would enhance the agent capabilities significantly. Adding the speech to text/text to speech loop and enabling a user to video call the agent would at least get me to the point where I have to worry about quality and hallucination. As it is, I’m not far enough along yet to begin to worry about this stuff.
For now, this idea will hit the shelf and I’ll either get back to working on my current side-project or a new one. I’ve got some ideas around neural nets in general that I think it might be time to explore.