
Building on LLMs

Generative AI and LLMs are all the rage these days. VCs are throwing cash at any pitch deck involving AI and AI-based startups are popping up like mushrooms in a field on a misty morning. A steady stream of academic papers of varying ranges of quality is pumped onto Hacker News daily. It seems like if you’re not working on something involving AI, you’re a weird luddite and you should be shamed - especially within the tech startup community.
Naturally I’m no different.
I’ve been tinkering with LLMs in various forms over the last few months. Actually I played with private-gpt when it first hit HN and experimented with integrating against OpenAI’s ChatGPT API almost a year ago, so longer than a few months.
Lately my focus has been more on open/community maintained models and running models on infrastructure under my control. My current favorite stack is ollama/mistral7b text model variant, running locally on CPU with eventual plans of experimenting with running models on GPU.
I’ve learned a few things within that niche that I felt were worth sharing for anyone else on a similar journey.
Before I launch into the technical-ish learnings, I want to write a little on why I’m focusing on open/community models and “local” hosting. I have many voices in my head (that sounds scary but it’s not literal) and every time I consider this choice, one of them yells loudly at me that I’m wasting time and should just build on the big daddy LLM model, ChatGPT 3.5 (I can’t afford 4, are you kidding me?)
For sure, I’d get more done and actually get to explore the business side of what I’m trying to build. I’d build a management UX, set up appropriate databases & vector stores, build out a client UX, etc. I might even launch way sooner and validate the idea and start making money. But that foundation would always be built on someone else’s land.
That’s a big problem, for a handful of reasons. The core part of my product is at the mercy of someone else’s decisions and it presents an unavoidable and uncontrollable expense line on any money making ventures. Overnight, OpenAI could decide to change their policies or pricing structures in a way that effectively puts me out of business. Reddit did it, Unity tried to do it, so there’s no reason OpenAI couldn’t do it. Even if the pricing remained the same for the rest of time (haha), OpenAI as a company could change.
I think everyone can see that tech giants like Google, Meta and Amazon have their own agendas that are beyond mere “users” like us. Google is under investigation for antitrust (hi, Microsoft in 2001) and Amazon seems to be using their dominance in online shopping to push as many cheaply-produced low-quality products as consumers will tolerate. They’re clearly not the companies they used to be 10 years ago. Building your entire company on someone else’s platform is almost asking for trouble these days.
So, local models of community origin.
Challenge #1 - Compute
Feel free to skip to the next section if you’re totally fine building your castle inside someone else’s kingdom. One of the excellent reasons to use OpenAI, Anthropic, etc is that you don’t have to figure this out. Just pay for access, fire your requests at their API and hope that it doesn’t error out or suffer a latency spike.
Otherwise if you want to run local models, you’ll need to figure out how to secure compute. You have many options and all of them are expensive and relatively painful. While it is possible to develop locally using CPU on a quantized model, you must deploy on GPU. The performance on CPU isn’t there. Models perform best right now when loaded entirely into RAM (for CPU quantized models) or VRAM for GPU hosting.
A rough rule of thumb for compute capacity I’ve seen floating around the internet is 1GB per billion parameters. So your huge Falcon 180B model is going to need ~180 GB of VRAM for real time performance. That’s ~3 Nvidia H100s and those go for between $30,000 - $40,000. Each.
Or you can rent one at $1.80 per compute hr.
I built a dumb simple multi-layer perceptron and trained it on the TinyStories dataset on my M1 Macbook Pro. Actually not the entire dataset, just a sample. It took ~10 hrs overnight and was junk because of a mis-placed parenthesis. That’d be a fast way to burn $18 with nothing to show for it. Do that a few times a week and you’ll be feeling the pinch.
Challenge #2 - Tooling
The wonderful thing about the open source community is that everyone shares their code. Usually if you can imagine a thing exists and you’re working in a reasonably popular programming language, someone has done it before. In fact these days, I almost never start a project by writing code - I go research the functionality that I can copy from someone else and smoosh it into my stack.
As stated above, everyone and their dog is working on an AI project, or product or startup. There’s lot’s of code out there (mostly in Python) on how to work with LLMs, both local community models and closed commercial models.
All of that code uses HuggingFace, Langchain and OpenAI.
Which is great. Except I don’t grok Langchain’s benefits over hand rolling your interactions, especially with models that have a robust API, and I don’t want to use OpenAI if I can avoid it. HuggingFace is pretty cool.
If you ever stray off the beaten path, you’re gonna have to hack code to get a lot of these cool libraries working. Given how faint that beaten path is now, suffice to say that it’s not for the faint of heart.
Projects go dead or dormant, or stagnate for 6 months and then release a new version that completely changes the API (I’m looking at you, Guidance). Working on an LLM based project for more than a month means changing libraries, reading source code and kludging things together from half broken, half discarded projects. I’ve basically taken to forking these projects into my own private org repos so that I can pin down versions and stop the ground shifting under me for a few minutes.
Challenge #3 - Lack of Peers
As I stated above, there’s a fair bit of code floating on code hosting sites for working with LLMs. Most online examples are overly simplistic and will perform some kind of cute demo. That’s great if you want to build a product to re-write proverbs but focusing on AI instead of the religious experience, not so much if you want to do useful tasks for which you can charge people money.
Nobody is really sharing the guts of their cool new AI idea, so you’re going to need to do a lot of discovery on tools, techniques and data mechanisms that achieve what you want to do. If someone is doing something novel with an LLM, that’s their moat, as shallow and small as it is. They’re not going to put that secret sauce out in the open for anyone to come along and copy. They also probably won’t write about it, unless it’s part of their go-to-market strategy.
But everyone’s doing LLM work, so finding knowledge and expertise should be easy, right?
As it turns out, most of the people who are online talking about AI the loudest don’t know how it works, and those that do know how it works and how to improve it spend most of their time writing research papers, publishing them on Arxiv and tweeting amongst each other. The rest of us are just out here “prompt engineering” to prevent this technology from devolving into hallucinatory conversations with itself.
Chances are your co-workers know about as much about LLMs as you do. It’s the blind leading the blind out here.
Challenge #4 - Production
The actual speeds of these LLMs when you try to use them are slower than published results. If you think about it for a few minutes, this makes total sense. Companies like OpenAI, Microsoft and Google have unlimited taps of money to power their unlimited taps of computation. Couple this with the toy-like demos that seem to go hand in hand with any technical writing on these topic, and you get impressive token/per second generation times that don’t live up to reality.
That’s also assuming the model and the hosting service have a 100% up time and service every request you send it. Dodgy networks and over-scheduled shared resources means this rarely happens, at least for me. As I write this, I tried to log into the OpenAI ChatGPT interface to screenshot the 20 req/hr limit on GPT 4.0, but found I couldn’t even log in.

The system status page also paints a relatively non-rosy picture of it’s availability.

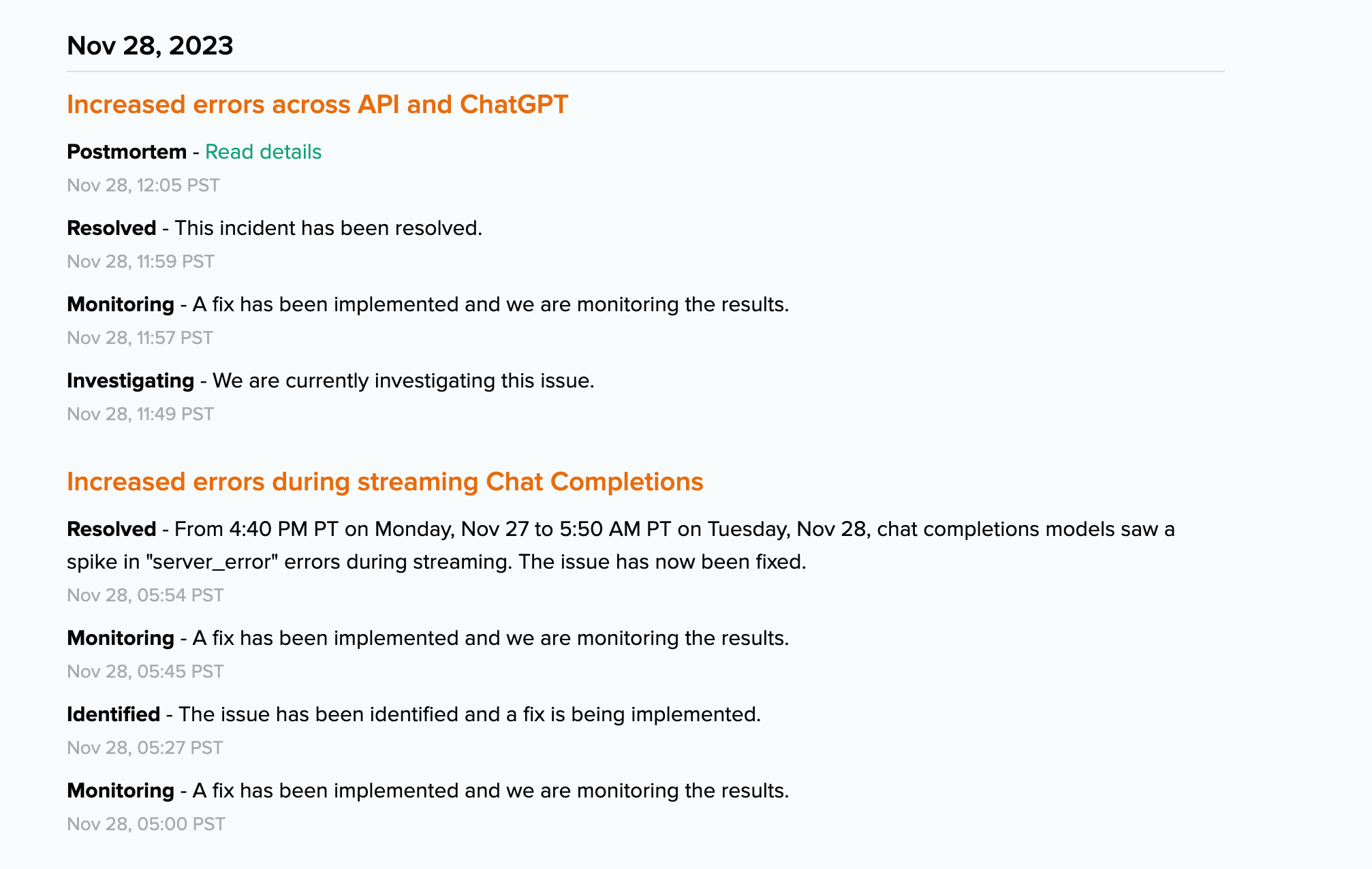
You will run into these errors in production. I promise you.
Even when things are going swimmingly, either you’re hosting your own community model and so you’re paying for every second of compute, or you’re sharing your platform with other people and have no control over your % utilization of that resource. If you’re running your own models, I doubt you can afford to run on the aforementioned Nvidia H100, so you’re probably running on underpowered hardware.
You won’t get the tokens/sec advertised in the papers or on the model cards.
Add in the random unreliability of networks and the fact that you’ll probably need multiple round trips to the LLM to complete anything meaningful (more on this in the next section), and things start to slooowww down. If you’re relying on ChatGPT or LLM models to provide a new paradigm of UX, you’ll have to anticipate the poor speeds, latencies and performances.
Challenge #5 - LLMs kind of suck
For what they are, LLMs are amazing. Like giant markov generators on steroids, it’s truly impressive what we’re able to do by compressing years of computation into a giant blob of numbers in an array.
Having said that, they still suck.
This is usually a function of the user’s expectations being wildly out of calibration with what the tech is able to do. Time and time again you’ll see arguments online about whether or not LLMs can reason, and whether they contain an internal representation of the world and understand things.
Regardless of the theoretical arguments, having worked with these things on and off over the last few months, I’ll say that it doesn’t matter. Whether they can reason or have an internal life is immaterial to the fact that they will confidently lie to you and make shit up and tell you it’s as true as the sky is blue.
The end effect is that you can’t use LLMs to do deep meaningful work.
As an example, take my recent goal of building an LLM powered ed-tech product. I built a quick proof-of-concept of a student enrollment using an LLM. The LLM’s goal was simple: ask the user questions to fill out a profile. The profile had a small amount of information, name, age, effective grade and a list of interests. I had intended to use the LLM to parse the natural text of a user chatting with it to build up a profile then emit it to my permanent storage solutions.
I got it working, and it was able to have a coherent chat with the user and gather the required information. Boy did I have to baby sit it though. Depending on the prompt, the model would:
Misinterpret a one-shot example as the user’s prompt, and fill it in with nonsense and not even ask the user a single question
Devolve into generating an entire conversation between itself and a user played by the LLM, resulting in a nonsense profile that had no bearing on the user’s input
Randomly ignore my prompts to output just JSON and prepend/append pleasantries that interfered with integrating with it
Granted, some of this was with OpenAI ChatGPT 3.5 and 4, and some of it was against a base Mistral7b quantized model. I understand that base models with no fine-tuning are basically useless, but if you need to fine-tune an LLM with every use-case you want to use it for, are you really saving time and money?
Recommendations
Would I recommend you start to leverage LLM tech inside your products/business ideas? Absolutely, as long as you understand what you’re getting into.
LLMs right now are the bleeding edge of AI tech. The capabilities, tooling and knowledge is changing every day. This isn’t some mature 10 year old tech and so the rules are a little different. There are things you can proactively do to make working in this space a little less painful.
Read. A lot.
Just today I opened 3 Arxiv papers into new tabs in my browser. I have ~90 tabs of various papers, blog posts, Github projects and articles about LLMs and modern AI research in general that I need to go through, read and synthesize. The field is changing rapidly, the tooling is changing rapidly, and everyone is writing about their cool thing and publishing results. Read them. Stay up to date with what’s going on. Learn what papers are actually useful and show something new, and which ones are just to pad out an academic resume.
Reading papers is hard. I don’t understand 90% of the math in them. I can unroll simple math equations into code, but once we’re deep into the linear algebra my brain checks out. Dig in, work through it and understand what you read - it will be worth it in the end.
Do Smaller Tasks
Even with the ever growing context lengths, just like a real person, an LLM has trouble coherently holding all 200k of your tokens in it’s “mind” at once. The longer your prompts, the longer your contexts, the more forgetful LLMs seem to become and the more they start to hallucinate.
When running my base quantized Mistral7b model, I could get ~20 question into the model before it’s performance would take a significant nosedive. Hallucination rates increase, in-accuracies increased and the changes that it would devolve into nonsense behavior increased.
I’ve found the best results with sticking with short, easy to self contain tasks. Above where I mentioned building an LLM powered user registration, I had a whole hierarchy of hand rolled boilerplate over the LLM API calls to ensure that conversation memory was being retained, properly fed back into the LLM via the prompt and feed the LLM different prompts depending on the task. These shorter tasks plugged together with less “running memory” required to complete them performed better than trying to do complex tasks in multiple steps.
Make LLMs chat to LLMs
Smaller tasks? Why the hell am I even using an LLM in that case? Can’t I just code it straight up?
Yes, but no. You can do longer, more complicated tasks using LLMs but the key to performing them well is to chunk the tasks, and loop it back to the LLM.
Going back to the task of building a user profile using an LLM powered chat interface, one technique I found very helpful was to use the LLM to validate user input/LLM responses.

Categorization, summarization and completion are things that LLMs do extremely well. Formulating a problem in a way that can be solved by completion, even in multiple calls to the LLM tends to out perform trying to get the LLM to write code you eval (this is unsafe!) or performing complex tasks involving math or reasoning. I had the best success working with LLMs if I ask the LLM to evaluate it’s own output, or the user’s input.
Conclusion
Working with LLMs is fun and exciting - it’s making me feel the same kind of magic when developing that I used to feel when I first started. However it’s not without it’s own unique set of challenges and frustrations. Remembering that you’re on the bleeding edge of tech and optimizing your work for flexibility and change is going to be the most effective way to work at this stage.
By all means, don’t take my word for it. Do your own development with LLMs and learn what works best for you, then write about it! The more deep technical information we have, the most use we can make from this technology.